



Features

Architecture
Technical designs and discussions about cloud-based systems.

Software
Articles and diagrams on writing code and solving technical problems.

Management
Running a company and working with teams of engineers to deliver quickly.
Consulting
Fintech, banking, and enterprise systems consulting.
Architecture
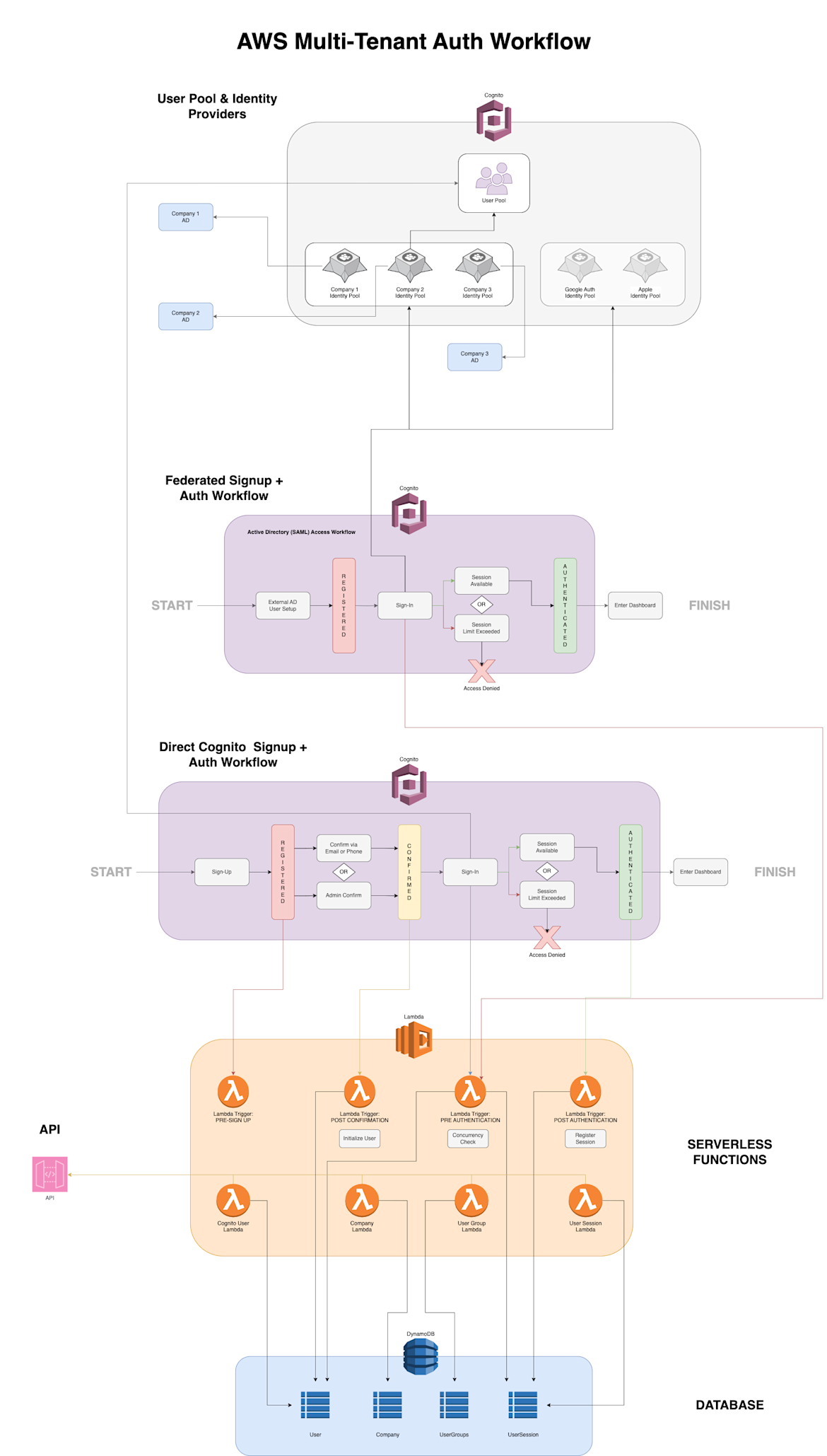
Scalable AWS Multi-Tenant Authentication: A Comprehensive Guide for Engineers
AWS multi-tenant auth system using Cognito, Lambda, and DynamoDB. Supports federated and direct login, custom workflows, and scalable serverless backe...

AWS AppSync Explained
A comprehensive dive into AWS AppSync with examples of different features and query designs. Learn how to use Lambda, DynamoDB, and HTTP data sources ...

Real World Observations on CI/CD
Describes the transformation that happens in software development teams when CI/CD is embraced, developers own code through to production, and releasi...
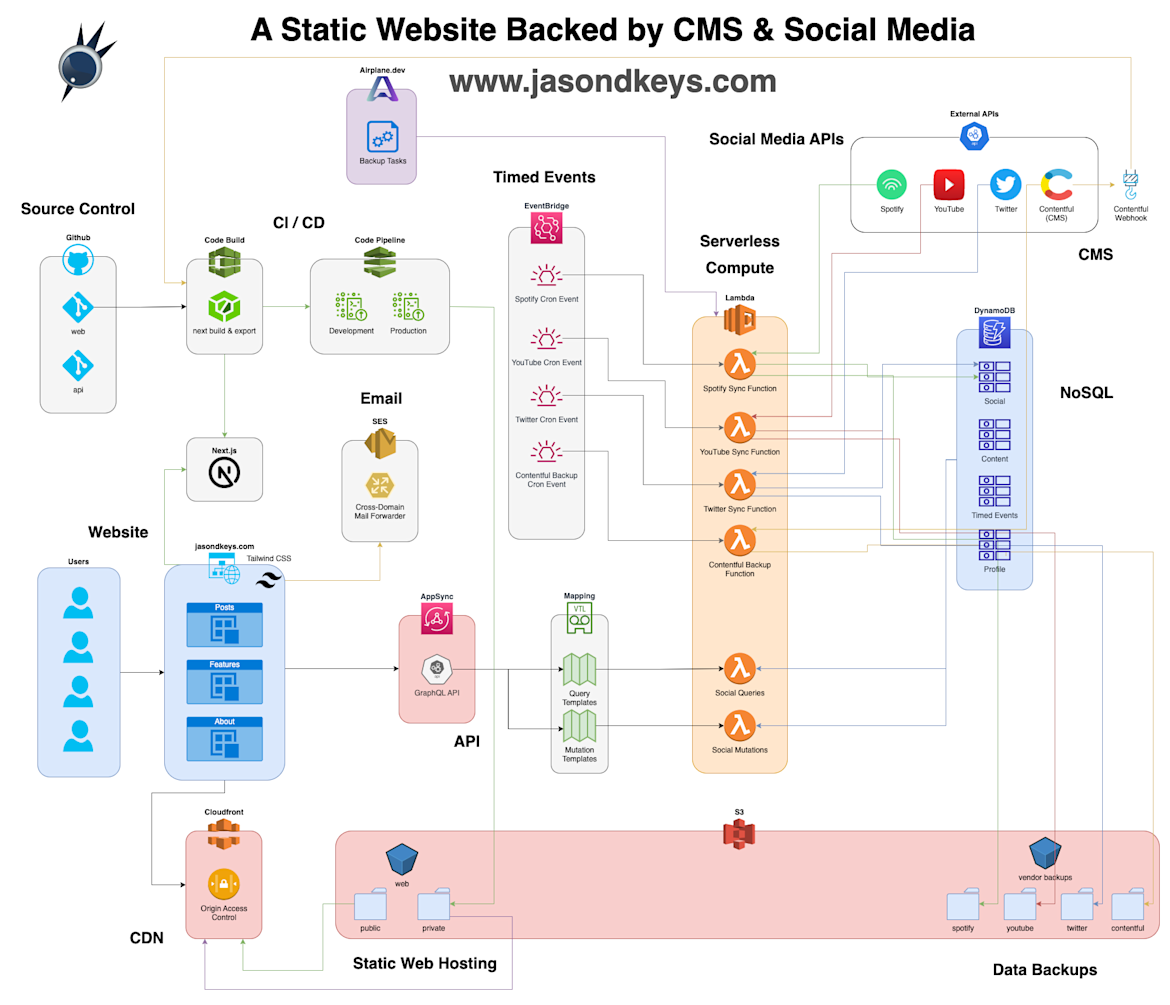
A Dynamically Static Website
Check out how this website works, the technology and tools that come together to make a static website come alive, and how it costs nothing to run.
Latest Videos
Johnny Cash - Big River
More Videos
All Posts

Electron: A New Tool for Cross-Platform App Development
Source code for an Electron Text-to-Speech app using AWS Polly is presented and discussed in detail. The Electron framework is discussed in detail in ...

Running Stable Diffusion in AWS
Describes a natural evolution when creating videos with Stable Diffusion Deforum whereby self-hosting and managing compute resources with robust graph...

Soliciting Jobs for My AI Voice
I apply for a narration job using a demo created using ChatGPT and my synthesized voice. Let's see if I can get a job through a video of me saying wor...

24 Hours of Watch Time
I discuss creating and testing YouTube Shorts and the first video to pass 24 hours of watch time. I reflect on analytics and the process of creating v...

AWS AppSync Explained
A comprehensive dive into AWS AppSync with examples of different features and query designs. Learn how to use Lambda, DynamoDB, and HTTP data sources ...

My Midjourney Profile
Here's a link to my Midjourney portfolio. You can check out all the images I'm creating for use on this site and my YouTube channels.

Generative AI Art Links
A collection of links to begin generating AI art both in the cloud for free and locally on your computer. Follow along with the links I used to go fro...
Real World Observations on CI/CD
Describes the transformation that happens in software development teams when CI/CD is embraced, developers own code through to production, and releasi...

Synthesizing My Voice
I use ElevenLabs Speech Synthesis tool to synthesize my voice in minutes. Now I have a vocal clone I use to read my articles and say whatever I don't ...

Deforum YouTube Shorts 6
The Wu Tang Clan, AC/DC, and Jay Z show up in 3 more YouTube shorts created with Stable Diffusion Deforum, the Rev Animated model, and 2D/3D motion ef...

Deforum YouTube Shorts 5
I continue to post YouTube Shorts using Stable Diffusion Deforum. Here I set them against Pink Floyd, Drake, Jay Z and Kanye West. The channel is gain...

Deforum YouTube Shorts 4
Today I created 3 more videos with Deforum in RunDiffusion. I used the RevAnimated model, DPM++ SDE Karras Sampler and 3D motion effects to once again...

Deforum YouTube Shorts 3
More videos created with Deforum, Stable Diffusion 1.5 and RevAnimated 1.2.2 models, Euler A and DPM++ SDE Karras samplers, and both 2D and 3D oscilla...

Deforum YouTube Shorts 1
I use Stable Diffusion Deforum, Run Diffusion, and ChatGPT to generate YouTube shorts with incredible visuals and licensed music.

Deforum YouTube Shorts 2
I continue using Stable Diffusion Deforum with the RevAnimated model. Here are a few videos of ocean animals, Valkyries, and Formula 1.

Swapping Faces in Midjourney
I use the InsightFace analysis library bot in Midjourney to add my face to any image I generate.

Running Stable Diffusion Locally
Today I installed Stable Diffusion locally, launched the web UI, and used a model I trained previously on my own face to generate pictures of me in di...

Stably Diffusing Myself
I use Dreambooth, Google Colab, and Hugging Face to train Stable Diffusion on my face so I can generate pictures of myself in different worlds and sty...

Supercars Soundtrack
Here is the soundtrack I created for the Supercars video I posted to my children's YouTube channel. I did everything in single takes. So I just came u...
YouTube Shorts with Licensed Music
Here are some YouTube Shorts I've created the past few weeks that utilize licensed, popular music available when uploading a Short from your phone.

Kids Talk AI YouTube Channel
I created a YouTube channel on artificial intelligence that includes facts, fears and thoughts on the future presented by an AI child's voice. It is i...

Presenting Jay-Z with Pictory
I use ChatGPT and Pictory to create a video with quotes and lyrics from Jay Z. I'm able to finish the 4-minute video in 40 minutes. Check out the vide...

Some Wisdom from Jiddu Krishnamurti
I've started a YouTube channel called Rise and Shine Quotes that aims to resurrect the words of forgotten thinkers and present them in digestible vide...

Using Pictory to Present McLuhan
I use Pictory AI to create a four-minute video in under an hour. Now I can focus on testing different niches for my videos more quickly with the help ...

Sci-Fi Art with DALL-E
Here are some sci-fi themed outputs from DALL-E. With the right prompt, it can produce some very interesting images. And until Midjourney is available...

Midjourney: Banners and Landscapes
I used Midjourney to create background images, YouTube banners, and landscapes for videos, channels and games. I'm learning about animation and creati...

Supercars Video
I used Midjourney to create images of Supercars in an anime vaporwave style for a children's video. I wanted to see the cars at night in the rain stre...

ABCs Video
I used Midjourney to create some interesting mashups of letter and word for a children's video on the ABCs. Check out the video and some of the pictur...

Animals In Clothes Video
Here are some of the raw DALL-E images that became assets in my video "Animals In Clothes". I was trying to generate old-looking paintings in the styl...

Emergency Vehicles Video
Here is a video I made recently and the raw Midjourney images I used as assets. I was going for a Pixar Cars style because my son is currently obsesse...
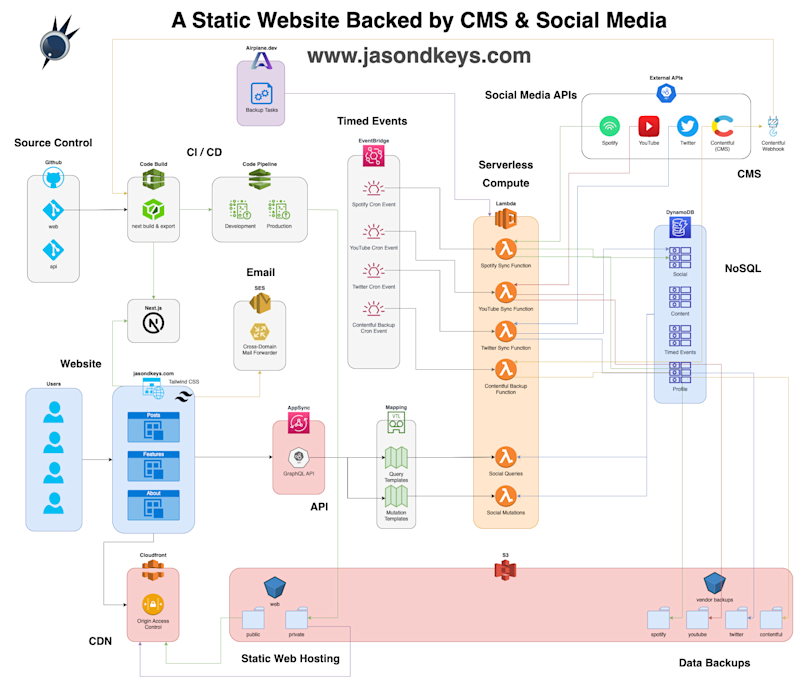
A Dynamically Static Website
Check out how this website works, the technology and tools that come together to make a static website come alive, and how it costs nothing to run.
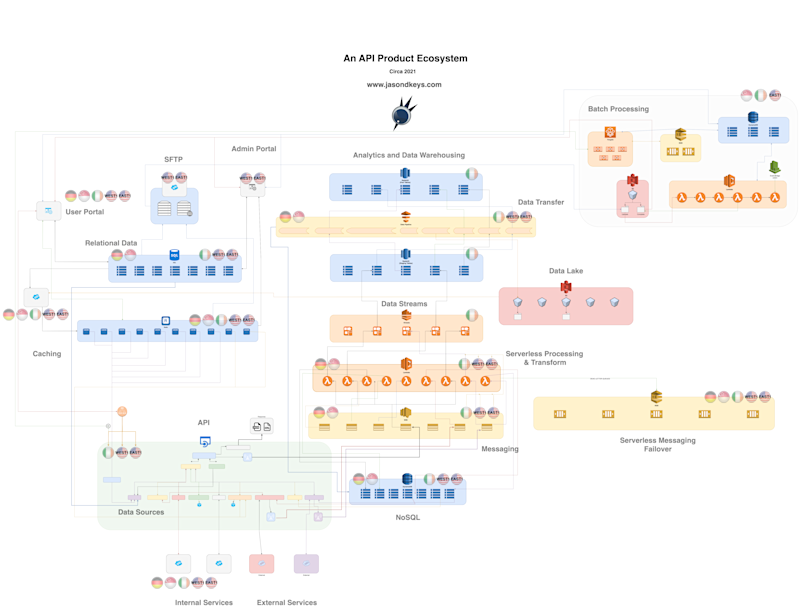
The Architecture of a Robust API
A technical picture that shows how a large API product may look in the AWS ecosystem, its web of connections and the high-level concerns in each area ...
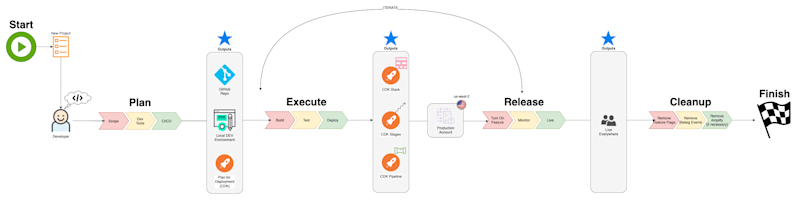
Code Releases and Competitive Advantage
Explores the changes CI/CD brings to company with an economic lens, seeing how the frequency of code releases represents a competitive advantage for t...

Outsourcing Web Development to AI
ChatGPT plays the role of teacher and junior developer to me as I build user interfaces and regain my sanity.

Learning the Developer Mindset
Discusses how software developers must continually reinvent themselves and learn new tools to stay relevant.
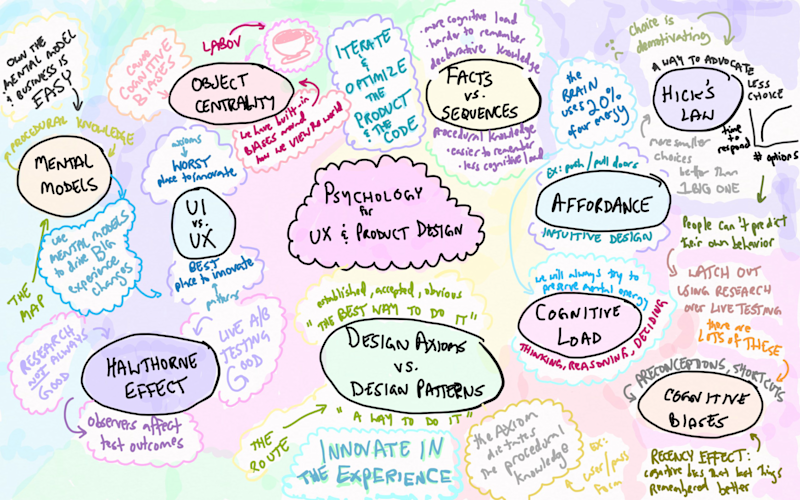
Psychology for UX & Product Design
Summary notes of an online workshop called Psychology for UX and Product Design where I learned about cognitive load, affordance and Hick's Law.
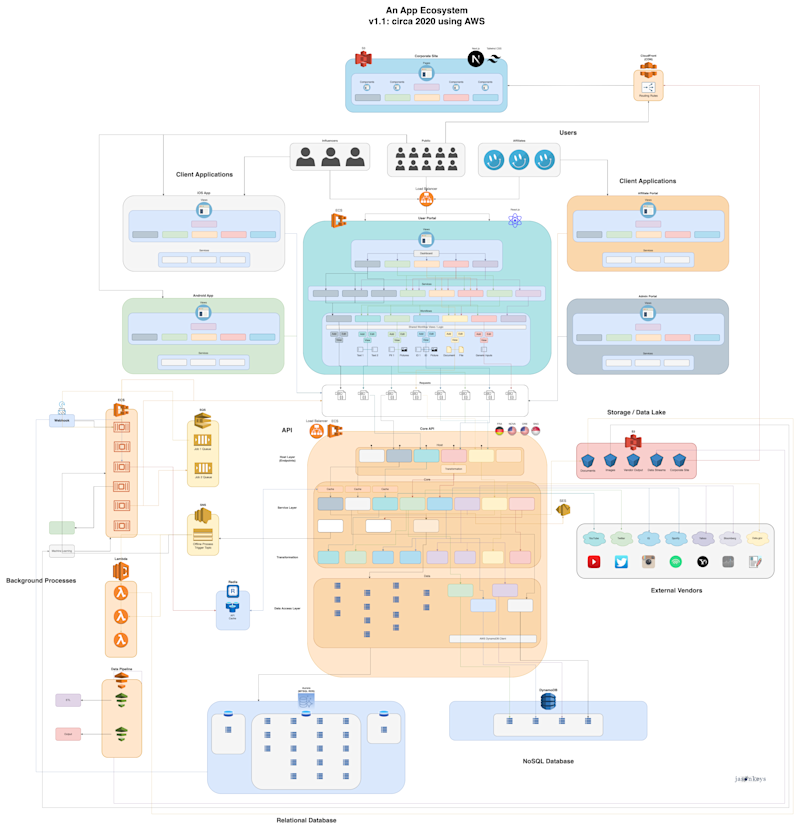
How I Make Technical Diagrams
Discusses how I collaborate on requirements, sketch out solutions, and produce beautiful technical diagrams.
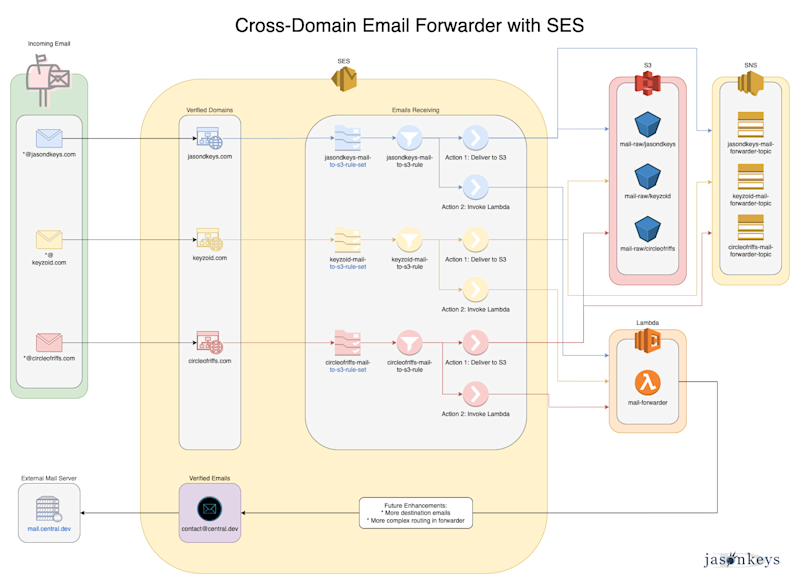
Implementing a Cross-Domain Email Forwarder with SES
Using AWS SES to forward disposable cross-domain email addresses to a shared third-party mail server.
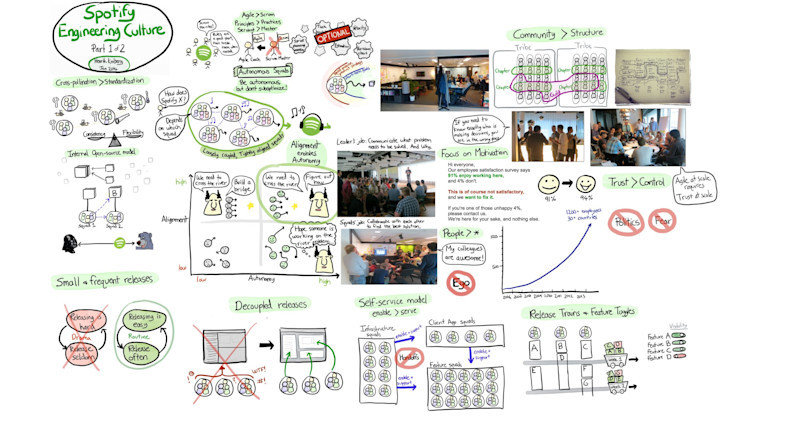
A Startup Story: How Dev Teams Take Control
How an engineering team takes control in a startup by controlling the speed and integrity of the release process.

Cartoon Poses and Cameos
I've always loved drawing cartoons. My school notebooks growing up had every inch covered with them. I still draw them all the time. Sometimes on a ta...
Quotes
"One of the highest pleasures is to be more or less unconscious of one’s own existence, to be absorbed in sights, sounds, places, and people."